利用云端计算资源
有时候你需要处理大量的数据,单机的计算资源无法满足这个需求。
抑或某个机器学习的任务需要特殊计算资源例如GPU来加速运算。但是本机没有这个计算资源。
或者你需要同时运行大量的相似任务,例如在某一个模型训练过程中尝试不同的参数组合。
在以上情况下,将本地的计算任务运行在云端是一个好的解决方案。ConvectHub也支持这些功能。
使用Dask gateway
Dask 是一个轻量化的并行计算框架。本地的代码只需经过很少的改动就可以运行在分布式的环境中。is lightweight distributed computing framework written in python and allow running python code utilizing multiple machines with/without minimal code change.
ConvectHub支持用户按需启动dask集群来加速运算。
如需启动一个集群,在notebook中运行如下代码
from dask_gateway import Gateway
gateway = Gateway()
options = gateway.cluster_options()
options

完成启动参数配置后,用户可以启动一个计算集群。
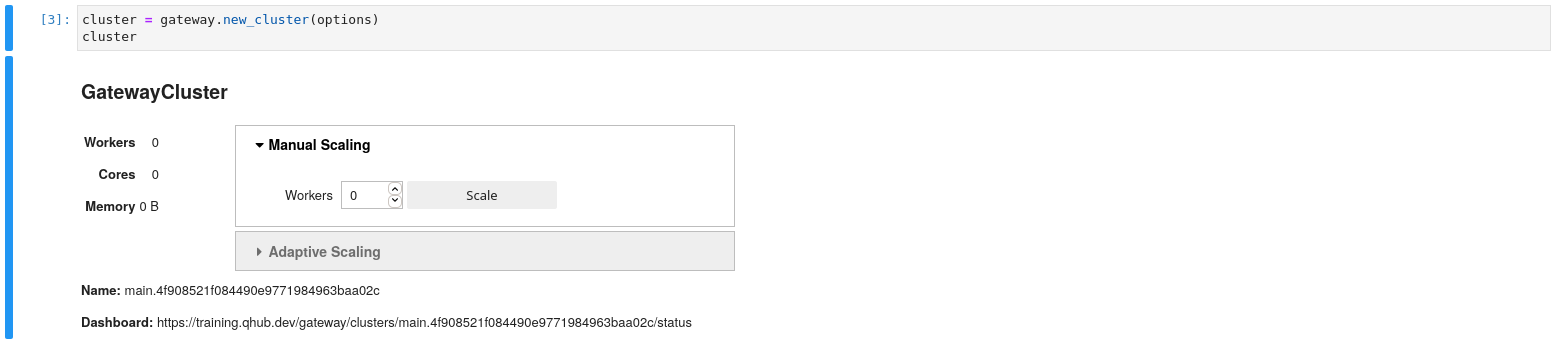
cluster = gateway.new_cluster(options)
cluster
用户可以通过可视化界面来动态缩放worker的数量。
cluster.scale(1)
启动完集群后,可以从本机连接到远程的计算集群
client = cluster.get_client()
最后,我们可以试着提交一些计算任务
import dask.array as da
x = da.random.random((10000, 10000), chunks=(1000, 1000))
y = x + x.T
z = y[::2, 5000:].mean(axis=1)
z.compute()
如果有结果返回则证明集群工作正常。
如需学习如何使用dask加速运算,参考文档doc。
远程执行一个notebook任务
用户可以将一个notebook作为远程计算任务提交。这个功能在如下情况下都很有用:
- 用户想要同时运行大量的相似任务,例如机器学习训练中不同的参数组合。在单机运行这些任务实在过于费时。
- 用户想要使用远程的计算资源。例如,使用比本地更多的CPU或者内存来加速运算。
如需提交任务,点击Run as pipeline。
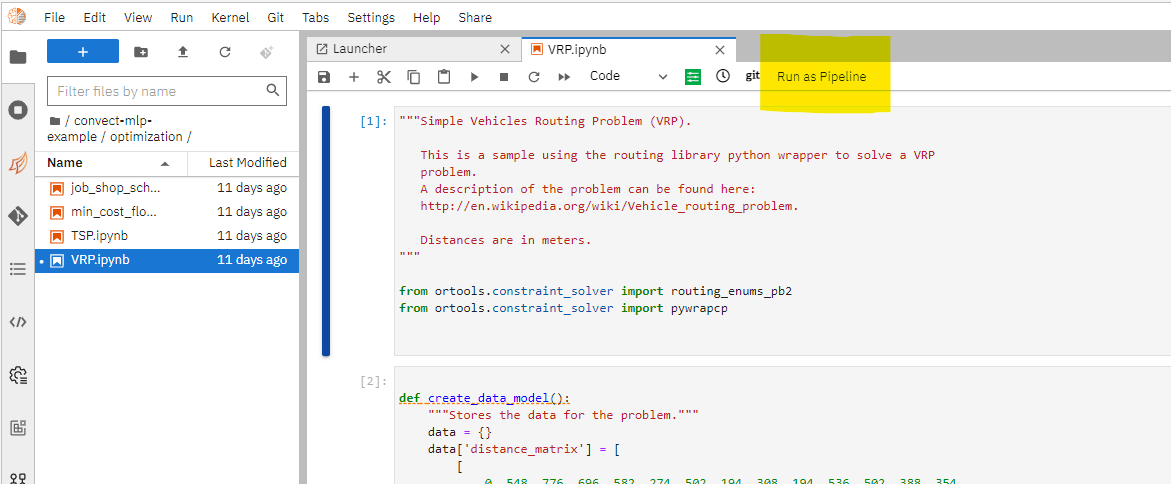
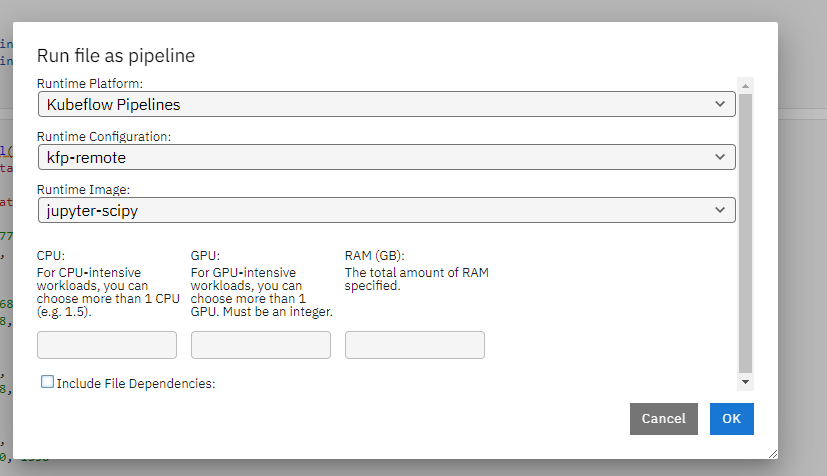
选择容器运行的image。作为一个最佳实践,应尽量保持本地和远程执行notebook的环境保持一致。同时可以申请运行任务的资源例如CPU内存GPU的数量。
成功提交之后,可以点击连接查看任务执行的详情。
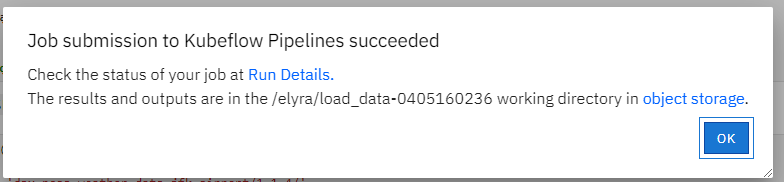
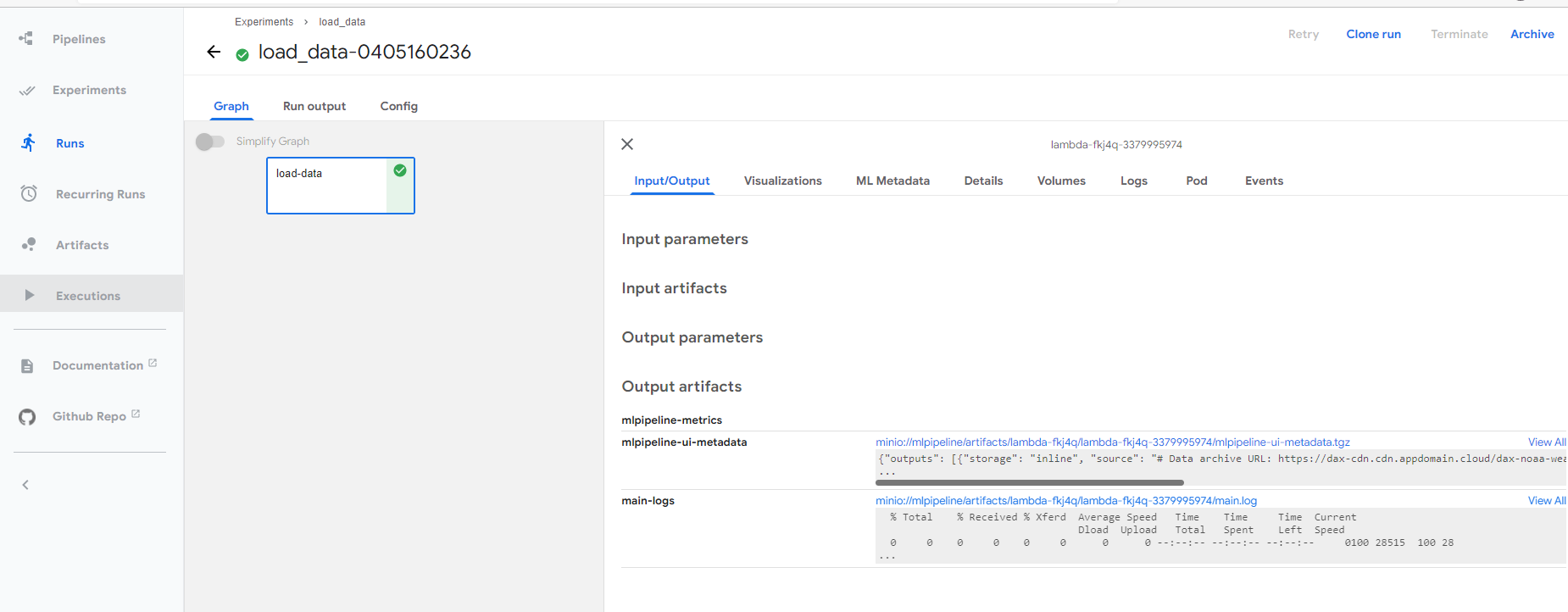
通过详情页的连接,可以直接下载执行完成之后的notebook文件。
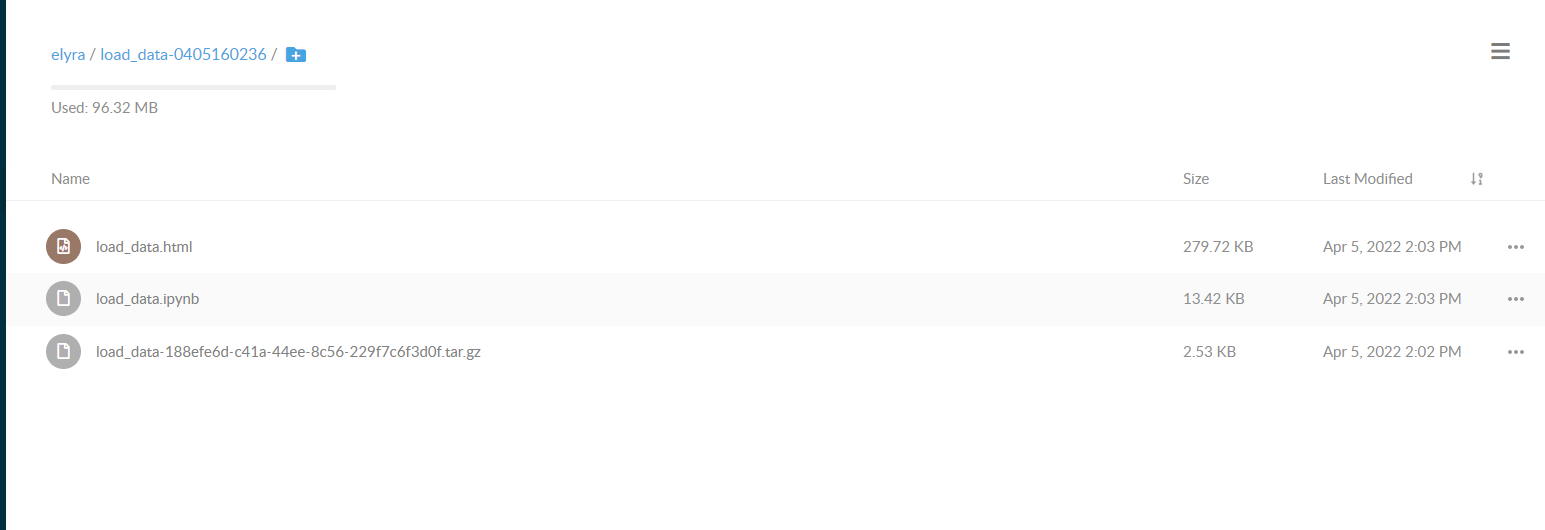
利用多个notebook创建管道任务
你可以利用多个notebook文件来创建一个可以重复运行的管道任务。这个功能对将一个复杂任务分解为若干小的步骤很有用。例如,在一个机器学习任务中,大致包含数据处理,特征工程,模型训练。模型评估这几个小的任务。在这种情况下,可以针对每个小的任务撰写一个专门的notebook。这样可以有更清晰的代码结构和管理。
如需创建一个新的管道任务,在启动器页面上选择"Generic pipeline editor",随后将文件管理器内的notebook文件拖拽到编辑区。可以将不同的notebook文件连起来来创建依赖关系。
右键某一个节点,选择详情编辑,可以对这个notebook的运行环境,资源需求,参数配置进行编辑。这个功能和上述的远程执行一个notebook任务是一致的。
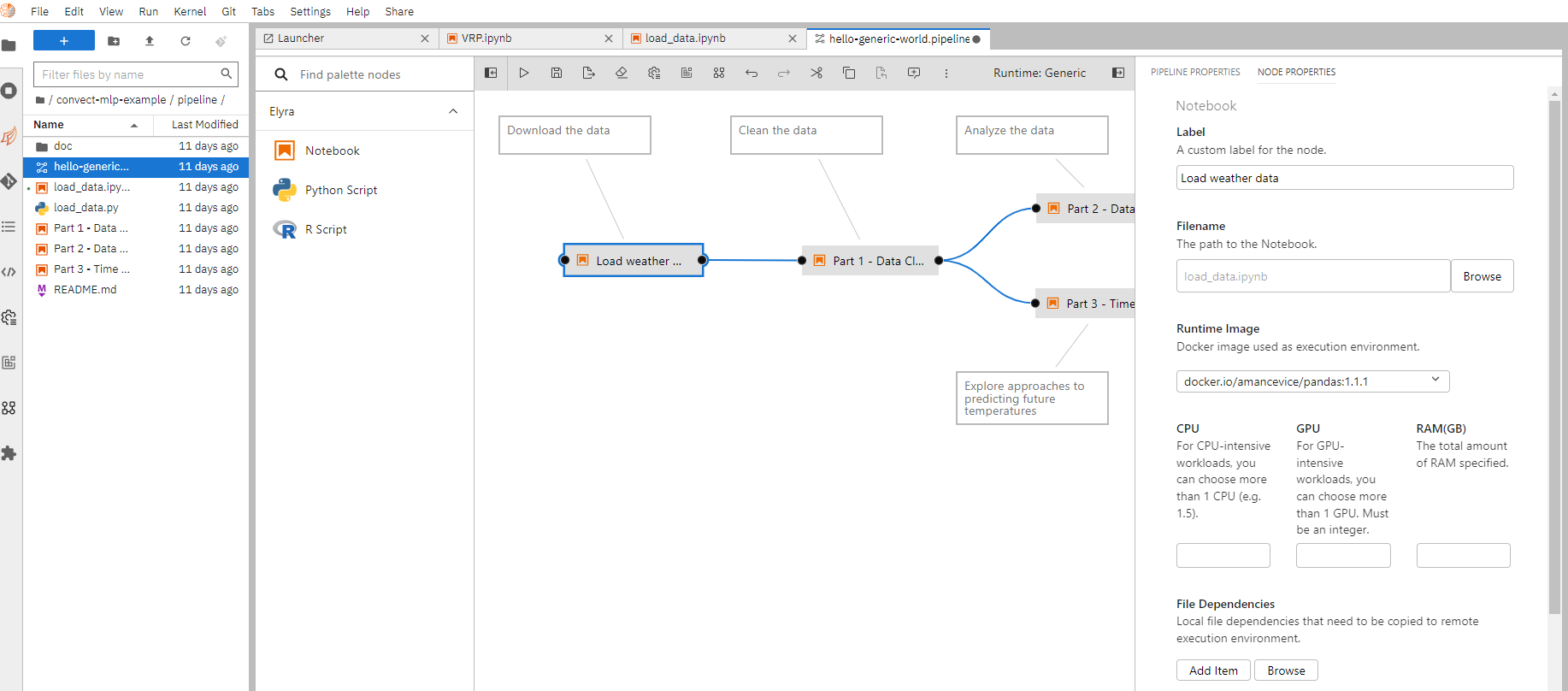
编辑完成之后,单机"Run pipeline"就会将这个管道任务提交。
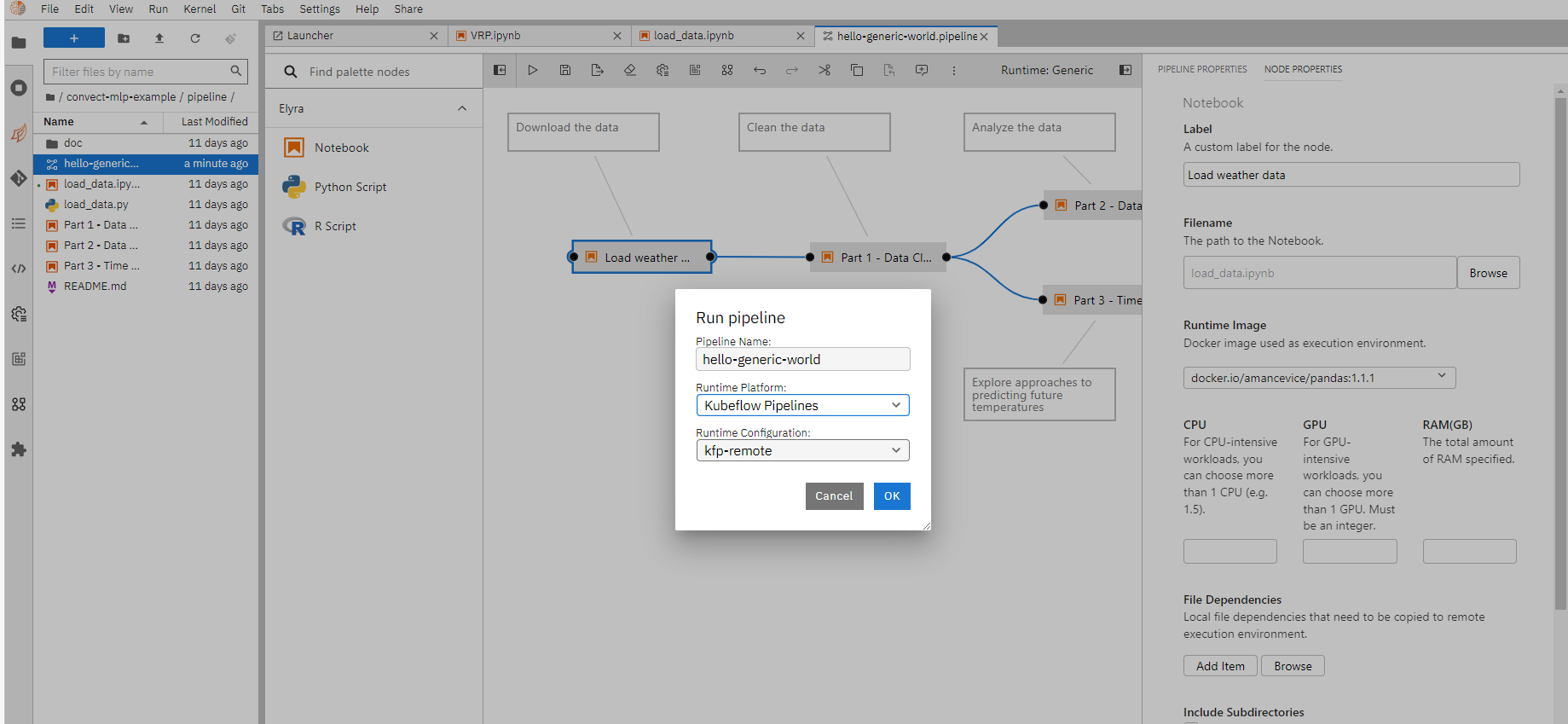
提交成功之后,可以通过链接查看具体的执行情况。也可以下载生成的notebook文件。
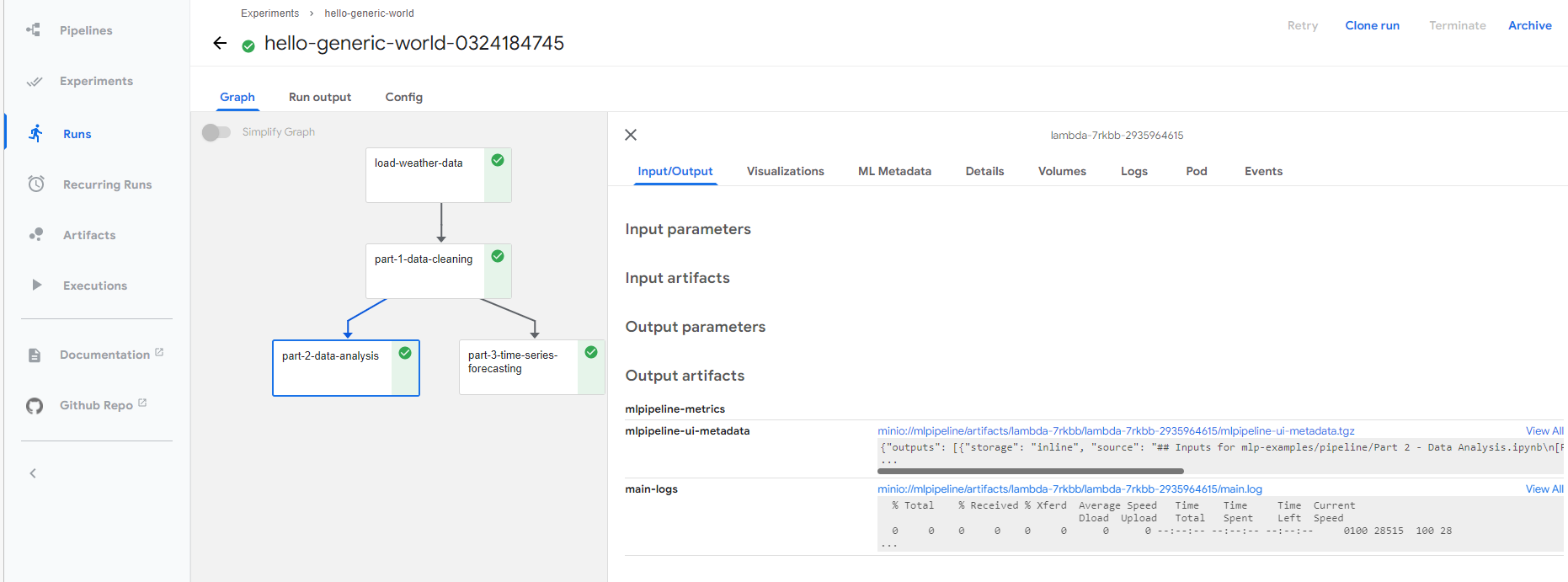
在管道任务中使用预制组件
在创建管道任务时,加入一些针对特定任务的预制组件对增加开发效率是很有用的。例如,一个可以接受销量作为输入,输出一个时序预测模型来预测未来销量的与之组件,对加快开发一个需要预测功能的数据科学解决方案是有益的。
ConvectHub支持导入任意kubeflow pipeline components,作为预制组件。
导入组件
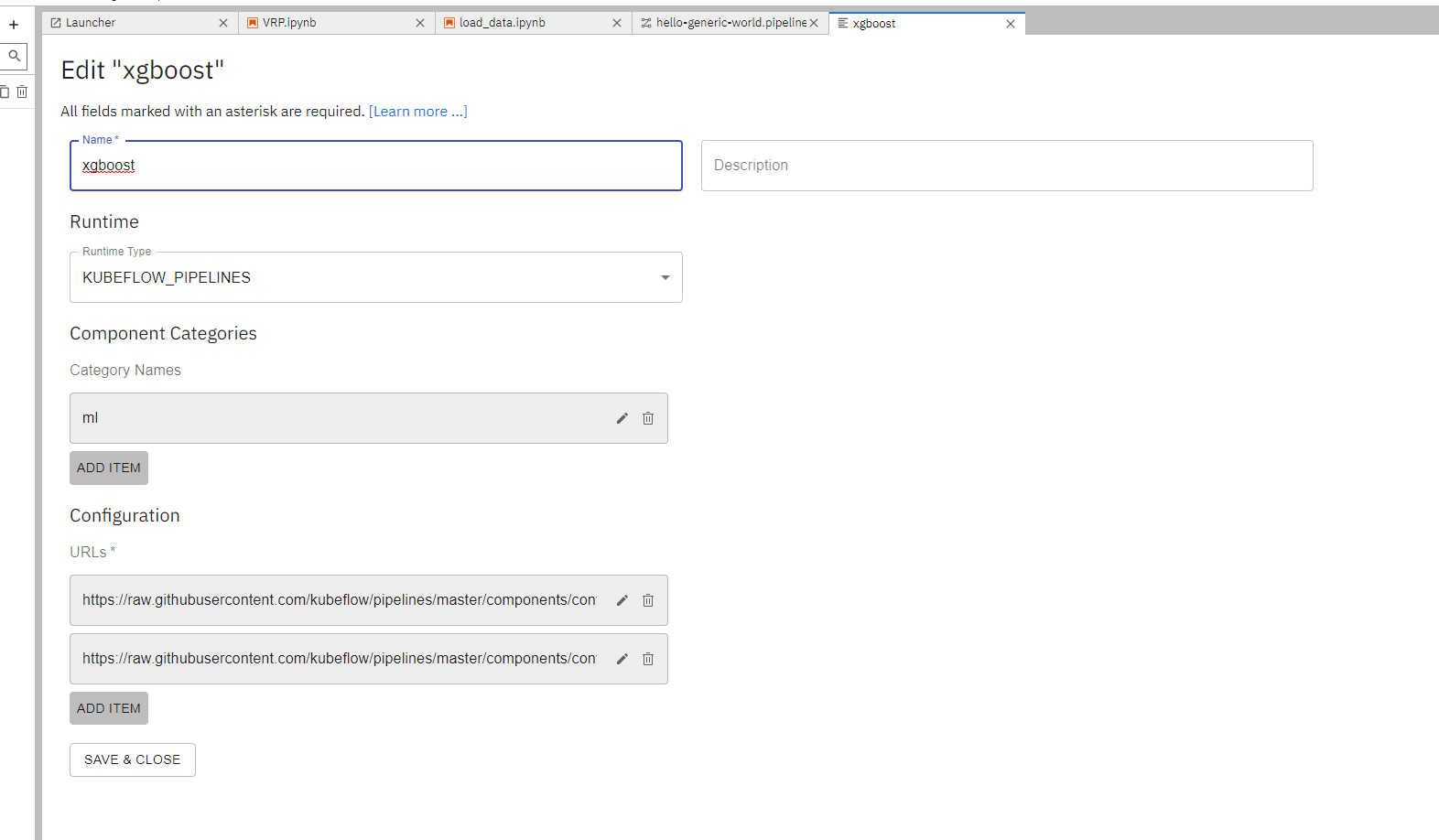
如需导入组件,首先需要找到组件的YAML文件的URL,例如https://raw.githubusercontent.com/kubeflow/pipelines/master/components/contrib/XGBoost/Train_and_cross-validate_regression/from_CSV/component.yaml是一个利用xgboost来做机器学习的组件。
选择"New URL Component Catalog",然后在Configuration板块下添加这个URL
使用预制组件
在完成导入之后,创建一个新的管道任务

在左边的工具栏上,可以看到刚才导入的预制组件,我们可以将它们拖拽到编辑区。右键详情编辑,可以设置组件节点的运行环境,资源和参数。
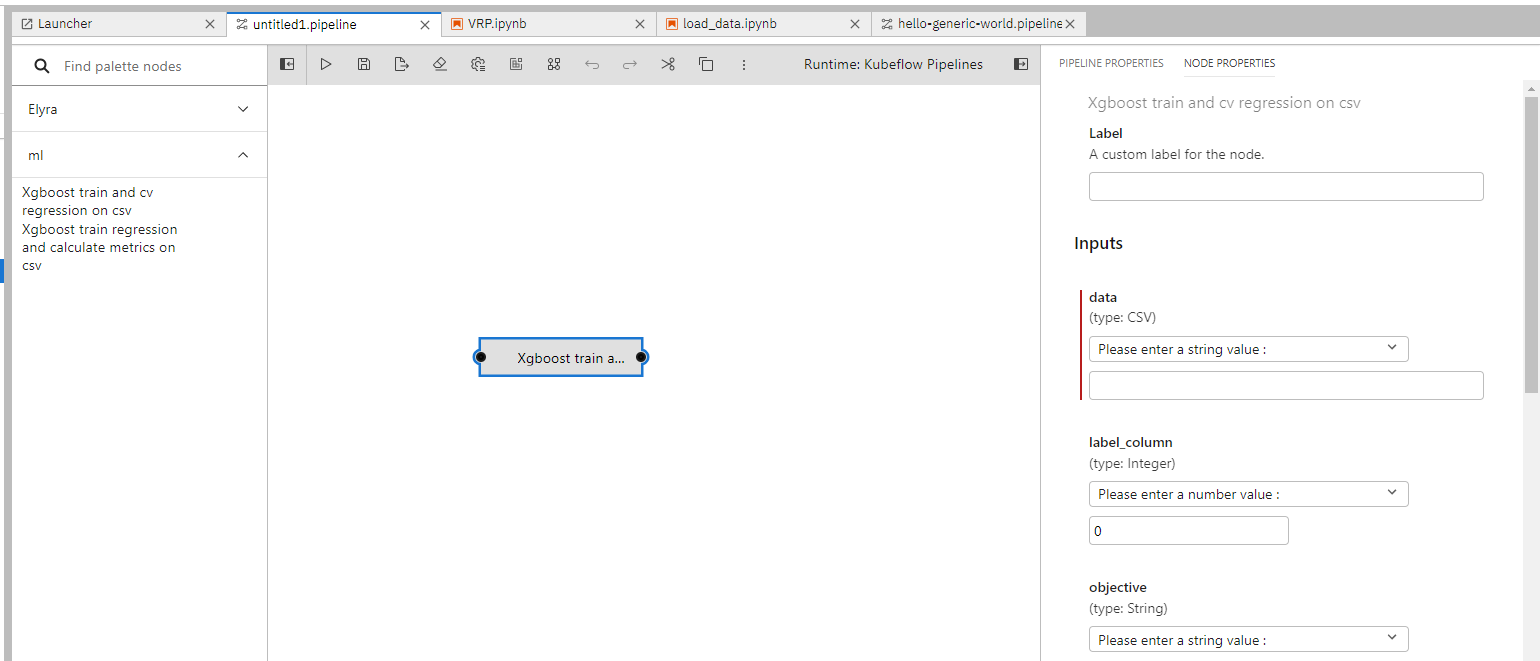
我们可以将这些组件和Notebook节点组合使用,从而生成更加复杂的管道任务。
分布式GPU训练
当我们训练大型机器学习模型时,使用多块GPU是分厂常见的。我们支持使用Kubeflow Training Operators,来完成分布式GPU训练。
提交一个分布式任务一般分为三个步骤:1. 将分布式训练代码打包为一个docker镜像;2. 通过yaml文件描述训练所需要的环境,例如GPU的数量,计算资源的需求等;3. 提交并且等待任务完成。
例如,如需分布式训练一个MNIST的分类器,首先我们将训练所需的脚本代码通过docker打包。
FROM pytorch/pytorch:1.0-cuda10.0-cudnn7-runtime
RUN pip install tensorboardX==1.6.0
RUN mkdir -p /opt/mnist
WORKDIR /opt/mnist/src
ADD mnist.py /opt/mnist/src/mnist.py
RUN chgrp -R 0 /opt/mnist \
&& chmod -R g+rwX /opt/mnist
ENTRYPOINT ["python", "/opt/mnist/src/mnist.py"]
随后将该镜像推送到registry。
docker build . -t mnist-simple:latest
docker tag mnist-simple:latest <YOUR_REPO>/mnist-simple:latest
docker push <YOUR_REPO>/mnist-simple:latest
完成后,我们定义如下的一个任务配置 job.yaml
apiVersion: "kubeflow.org/v1"
kind: "PyTorchJob"
metadata:
name: "pytorch-dist-mnist-nccl"
spec:
pytorchReplicaSpecs:
Master:
replicas: 1
restartPolicy: OnFailure
template:
metadata:
annotations:
sidecar.istio.io/inject: "false"
spec:
containers:
- name: pytorch
image: <YOUR_REPO>/mnist-simple:latest
args: ["--backend", "nccl"]
resources:
limits:
nvidia.com/gpu: 1
Worker:
replicas: 1
restartPolicy: OnFailure
template:
metadata:
annotations:
sidecar.istio.io/inject: "false"
spec:
containers:
- name: pytorch
image: <YOUR_REPO>/mnist-simple:latest
args: ["--backend", "nccl"]
resources:
limits:
nvidia.com/gpu: 1
我们在如上的配置中声明使用一个master和一个worker节点,它们各自有一个GPU。 随后通过命令行提交任务
kubectl create -f job.yaml
可以通过如下的命令来监视提交任务的状态
kubectl get -o yaml pytorchjobs pytorch-simple
欲了解更多使用Training Operators Doc的细节,我们推荐参考官方文档。